

Was bisher geschah: Ein neuer OfferCube Kunde beauftragte uns mit der Datenmigration all seiner Daten in das neue System oder besser gesagt „Bitte einmal alles Neu und extra scharf!“.
Heute gehts ans „Eingemachte“ 😉
Es handelt sich um eine MS-DOS Anwendung mit dem Namen „Pavlof“, erste Verwendung 1989, letztes Update von 1994.
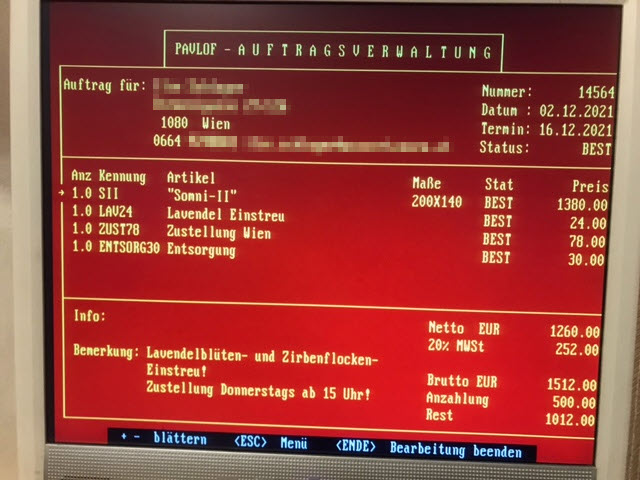
Kurzer geschichtlicher Ausflug:
1994 – zu der Zeit war gerade DOS 6.22 erschienen (ich startete gerade meine ersten Erfahrungen mit DOS 6.20, Borland C und Turbo Pascal).
Bei den PCs handelte es sich (wenn es High-End war) um einen 486er mit 4MB RAM (ja MEGA Byte, nicht Gigabyte!). Kleine Festplatten (so um die 80 MEGA Byte, ja wieder MEGA, nicht Giga oder gar Tera). Und Daten wurden über Disketten (3,5 Zoll, 1,44MB = MEGA Byte) ausgetauscht, nicht über Netzwerk oder gar USB-Stick.
Und so war bereits der Transfer der Dateien die erste Schwierigkeit.
Der etwas in die Jahre gekommene PC kennt noch keine USB-Sticks – schlussendlich wurde dies mit einem IDE (SATA, was ist das? 😉 CD-Brenner gelöst. Nächstes Problem – keiner unserer PCs besitzt mehr ein CD-Laufwerk. Aber da unser – nennen wir es „Archiv“ – gut ausgestattet ist wurde auch das rasch gelöst.
Also nun hatten wir 129 Dateien mit mehr oder weniger nichts sagenden Dateinamen im 8.3 Format (Siehe FAT Dateisystem aus DOS Zeiten).
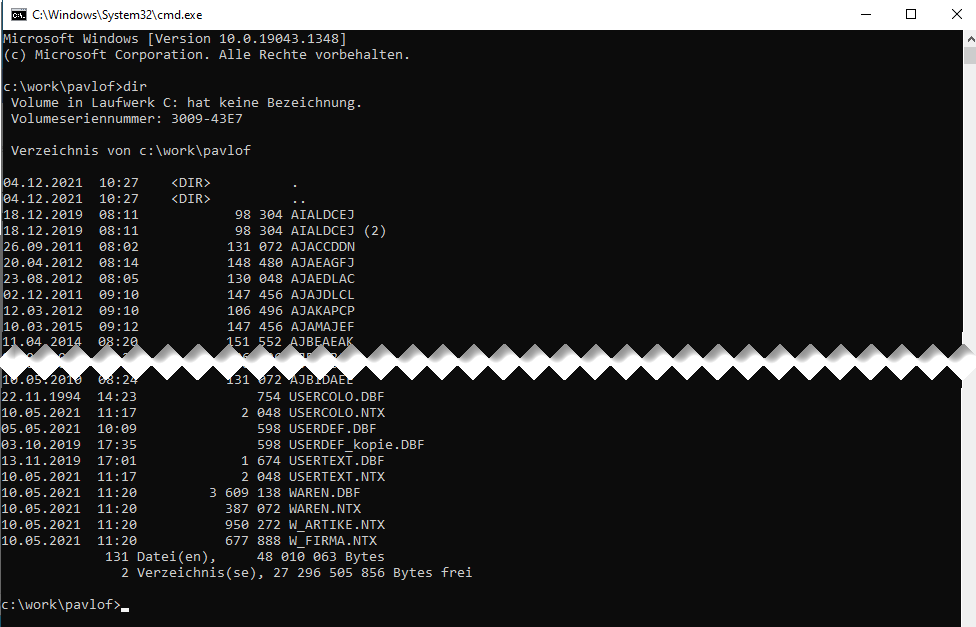
Der erste Schritt war nun, das Datenformat zu analysieren.
Meine Vermutung war, dass es sich bei den .DBF Dateien um Datenbank Dateien handelt.
Meine Hoffnung war, dass es ein bekanntes Format ist und keine selbstentwickelte Datenbank, wie es damals bei DOS Programmen gerne von Herstellern/Programmieren (ich bin hier keine Ausnahme 😉 gemacht wurde.
Um herauszufinden, ob die Datei ein irgendwie bekanntes Format besitzt, eignet sich das Linux Werkzeug „file“ hervorragend – ein erstes „file KUNDEN.DBF“ brachte das Ergebnis „KUNDEN.DBF: FoxBase+/dBase III DBF, 11827 records *“ – Sehr gut!
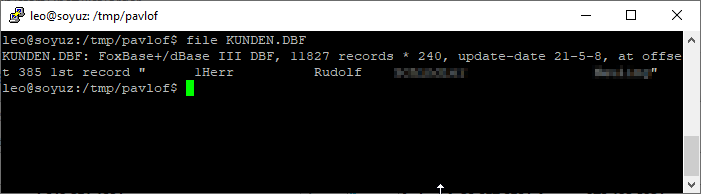
Es handelt sich also um ein altes dBase3 Format (Glück gehabt, keine Eigenentwicklung) und Fixlängen Felder – Feldlängen 10, 12 oder 25 Zeichen – restliche Zeichen werden mit Spaces (Leerzeichen) aufgefüllt.
Eine weitere Analyse zeigte, bei mehrzeiligen Feldern wird jede Zeile wiederrum mit einer fixen Länge abgespeichert – jedes Feld ist eine eigene Zeile wird aber wieder bis zum Ende mit Leerzeichen aufgefüllt. Der Text wird aber auch direkt im Wort in das neue Feld umgebrochen.

Nun war es an der Zeit eine Lösung zu finden,
mit der diese dBase3 Datenbanken einmal ausgelesen werden konnten, um die Daten zu sichten.
Die Wahl fiel auf php, da es mit der dbase Erweiterung die Dateien öffnen und lesen konnte.
Es wurde ein kleines Programm geschrieben, das alle DBF Dateien öffnete und jeweils die ersten 10 Datensätze in eine CSV Datei speicherte.
Beim kurzen Sichten der Dateien fielen gleich mehrere Dinge auf:
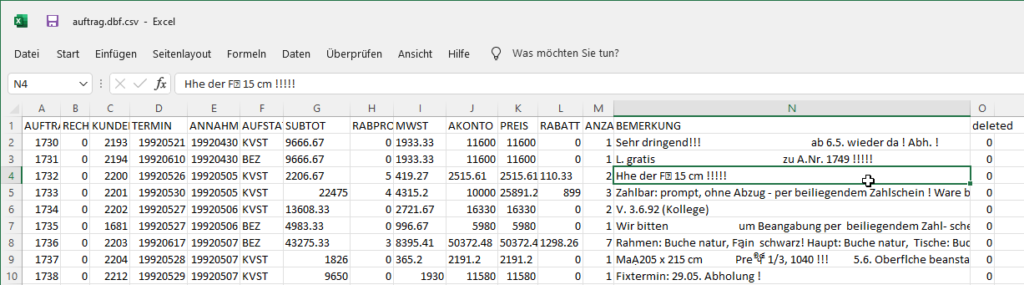
Die Umlaute werden falsch dargestellt, Bemerkung ist mehrzeilig, das Datumsformat ist YYYYMMDD und es gibt einen Auftragsstatus (aber dazu mehr beim Datenmodell).
Weiters gab es mehrere Datenbankdateien mit ähnlich lautenden Namen z.B. AUFTRAG.DBF, AUFT.DB, AUFTOLD.DB. Diese Dateien waren nicht nur Kopien, es waren ältere Versionen der Datenbank.
In den neueren Versionen kamen Felder wie z.B. deleted hinzu und eine weitere Erkenntnis (siehe Datenanalyse und Datenmodell).
Soweit so gut …
der nächste Schritt ist nun, das Datenmodell zu verstehen und so einen Migrationspfad zu entwickeln … to be continued …
#tellMeTuesday #OfferCube #CRM #Computer #Diskette #DOS